Ocr box editor. Canon Knowledge Base 2019-04-26
jTessBoxEditor
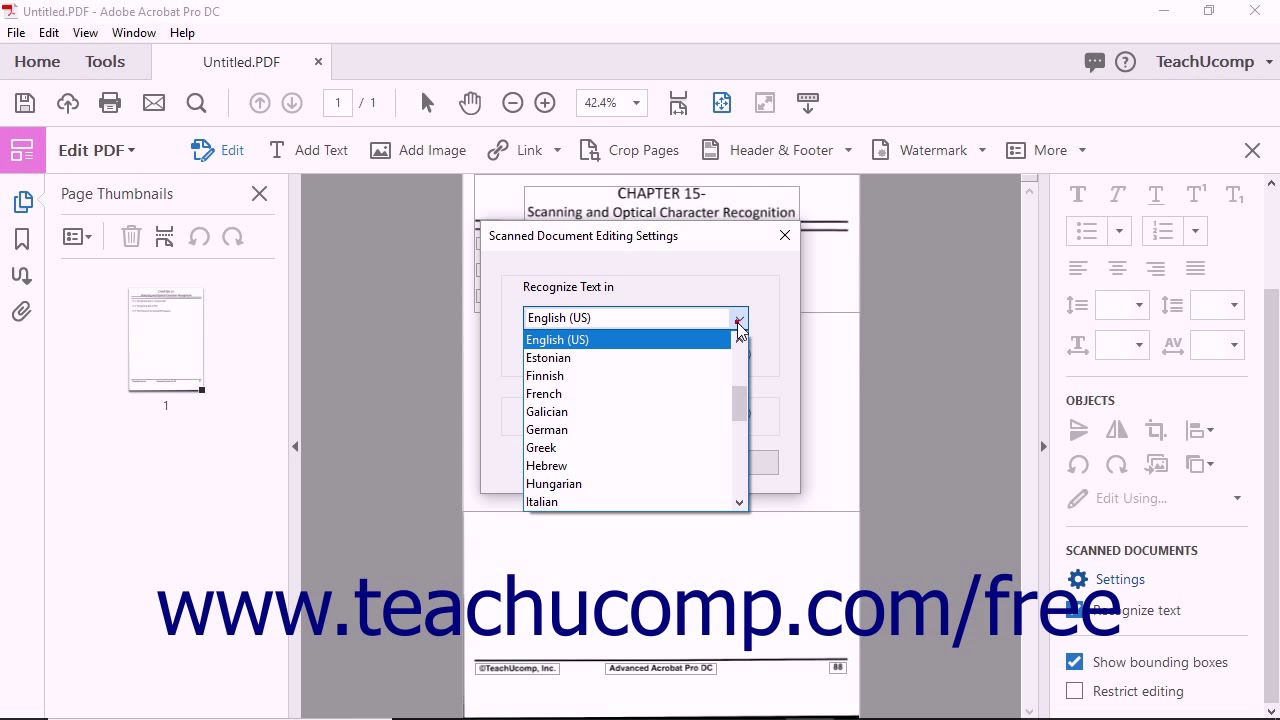
It can be configured to use a proxy server only for the connections that it creates. This method will not create a new document, and will alter the current document by adding searchable text. As you can imagine, the ability to automatically classify and label images provides dozens of powerful use cases for Box customers. The Scan Properties dialog box will open: 3. This is the syle in PostScript and files.
Boxoft Free OCR (freeware)

That's where Google Cloud Vision came in. If that does not resolve the issue, then please submit a support ticket at. With over 20 languages to choose from and a simple to understand interface it is perfect for any job and any user. User dictionary Select a user dictionary if you wish. You can download the program from. This action works on multiple rows. You need one or multiple files that together contain at least 1 but preferably more occurrence of each glyph of your font.
How to make a .box file for Tesseract OCR in C#?

Then your file will be list in the pop up window. The training process can also be automated using , a Windows PowerShell script. Thanks If you have jTessBoxEditor, then you have Tesseract bin files. Click the button to the right of the selection box to. Advanced table operations If you use training based on real scan usualy your image is not ideal and tesseract is not able create good box file e.
ocr

The side-by-side Image and Text comparable interface also helps a lot on editing 3. The edited box files are still read and written in proper format. This tells how you can do this. Metadata Document metadata contain detailed information about the document such as its author, subject, and keywords. I've also tried boxFactory but it doesn't run properly. We wanted to make image files as easy to find and search through as text documents. Bounding Box Editor improves recognition.
GitHub

Once done, you can verify by opening the image in jTessBoxEditor to check if the boxes match up with the image. You can select box also in viewer - just click on image box location and correct box will be selected in table editor box must exists. You can convert pdf files to tiff. You will need to customize it to meet your needs. Noise can optionally be added to the image, which could result in better trainned data. Other companies can license those technologies, but only for a fee that's usually passed on to you — the user.
Box

Aim of this project is to provide easy and efficient way for editing regardless file size. Working with patterns and languages You can save and load user patterns and languages. Some sites will email you a Word document or other file containing the text of your image for free, others will simply provide the text for you to copy. There are two main reasons for the use of this name. Short embedded texts in English can be recognized without English being selected as a recognition language. No flowing text zones will be detected. Detection is more robust with at least se veral lines of text and a minimum of embedded English text.
How to prepare training files for Tesseract OCR and improve characters recognition?
The latest released source is. It worked well and we did not spent much time on development. Also store reference to original image. Ctrl and Shift key can help you to make selection. Second, you can study it and adapt it to your own needs. The text layer contains identical text to that recognized in the document. If there is any question, please post in.
Box
I have adapted a Nautilus Python script which extracts archives. Additionally, it should be noted that setting the accuracy to high may result in unusual output if the document on which the operation is carried out features imperfections. For many applications this can be incredibly useful, being able to search a scanned book for specific phrases can drastically reduce research time for students for instance. But we had some problems with specific letters recognition mixing W and H, O and 0 zero. You can also setup box types and limit range of recognizable symbols. Apply the modifications with the command patch tesseractBoxEditor. When scanning is completed, the scanned images are saved according to the settings, and the extracted text appears in the specified application.
OCR
Letter tracking, or spacing between characters, can be adjusted to eliminate bounding box overlapping issues. Choose it also for a page with words or numbers arranged in columns if you do not want these placed in a table or decolumnized or treated as separate columns. Together, they cited information from. The right-bottom has the maximal values for x and y coordinates. I decided that to achieve the best accuracy I should train Tesseract with images preprocessed in exactly the same way as they would be in the final application. Note that some boxes could be slightly different by 1 or 2 pixels from the ones that would have been generated by Tesseract itself; nevertheless, the generated box file can be used to validate the one created by Tesseract with the use of a Unicode-compatible file compare tool, such as.
Alpha Forms OCR for business documents and forms. Medical claims, invoices, purchase orders.
Tesseract is very good at recognizing multiple languages and fonts. Once template is saved keep running recognition on all images that match template. You can create simple geometric shapes and— as with Sedja, above — add white rectangles to obscure parts of the document when it's printed. I had this same kind of problem with being unable to properly open images with jTessBoxEditor in order to work with their boxes. Each story has a comments section attached to it where intelligent and technically-inclined users discuss the topics at hand.